Data inlezen
Contents
2.4. Data inlezen#
Een van de belangrijkste redenen om gebruik te maken van pandas is dat het hiermee heel makkelijk is om data in te lezen vanuit verschillende bestandstypes. In deze instructie zullen wij kijken hoe dit werkt voor .csv bestanden en voor excel (.xlsx) bestanden.
2.4.1. CSV-bestanden#
Een .csv-bestand is een heel simpel databestand. Een voordeel van dit type bestand is dat het op bijna alle computers te openen is, en dat je er met heel veel programma’s mee kunt werken. Ook pandas kan makkelijk .csv-bestanden lezen.
Eigenlijk is het een bestandje met ruwe tekst erin, waarbij we voor elke nieuwe regel in het bestand een nieuwe rij aan data hebben. Op elke rij kunnen we verschillende kolommen onderscheiden met komma’s (,) of punt-komma’s (; da’s handig als je data zelf komma’s bevat). Een heel simpel voorbeeld van de inhoud van een .csv-bestand zie je hieronder.
Tijd;Afstand
0;0.003346737727484
0.1;0.553599135409783
0.2;1.22383023335605
0.3;1.89047687754027
0.4;2.45291862764642
0.5;2.8446041846015
0.6;3.0369855008415
0.7;3.03696568914571
0.8;2.87942416667373
0.9;2.61684688431892
1;2.30816167068372
1.1;3
Wij vinden het vaak handig om de databestanden in een losse map op te slaan, als submap van de map waarin je code zelf staat. Bijvoorbeeld in een sub-mapje data:
projectmap
|
├───data
│ ├── simple_csv.csv
│ └── andere_data.csv
│
├── mijn_script.py
└── ander_script.py
Als je mappenstructuur zo in elkaar zit, kun je met de volgende code (in het scriptje mijn_script.py bijvoorbeeld) de data inlezen.
import pandas as pd
data = pd.read_csv('data/simple_csv.csv', delimiter=';', quotechar='"')
print(data)
Tijd Afstand
0 0.0 0.003347
1 0.1 0.553599
2 0.2 1.223830
3 0.3 1.890477
4 0.4 2.452919
5 0.5 2.844604
6 0.6 3.036986
7 0.7 3.036966
8 0.8 2.879424
9 0.9 2.616847
10 1.0 2.308162
11 1.1 3.000000
12 1.2 1.762065
13 1.3 1.596348
14 1.4 1.521989
15 1.5 1.533724
16 1.6 1.614163
17 1.7 1.738634
18 1.8 0.500000
19 1.9 2.014380
20 2.0 2.122015
21 2.1 2.191604
22 2.2 2.219472
23 2.3 2.208948
24 2.4 2.168591
25 2.5 2.109939
(quotechar= is hier niet per sé nodig, omdat het bestand geen aanhalingstekens bevat. Wij voegen het wel vast toe voor het geval dat je ooit deze regel code kopieert naar een situatie waar het wel nodig is.)
De inhoud van het CSV bestand wordt nu opgeslagen in een dataframe genaamd data. We hebben hier twee speciale argumenten meegegeven aan de functie read_csv: delimiter en quotechar. Met deze argumenten vertellen wij pandas wat het van de indeling van het bestand kan verwachten. Niet elk CSV bestand wordt namelijk hetzelfde opgebouwd.
Door delimiter=';' te typen geven wij aan dat de velden van het bestand door puntcomma’s (;) gescheiden worden. Door quotechar='"' te typen geven wij aan dat de velden omsloten kunnen worden door dubbele aanhalingstekens ("). Dat laatste zou handig zijn als de data zelf ook punt-komma’s bevat.
Het is handig om altijd wanneer je een nieuw CSV bestand opent deze even in een tekst-editor te openen, dan kan je namelijk kijken wat voor tekens er zijn gebruikt en dit correct in je code aangeven. Wanneer je dit niet doet kan het voorkomen dat de velden niet goed herkend worden.
2.4.2. Dataset van internet#
We herhalen nu de eerder genoemde stappen, maar met een wat praktischer voorbeeld. Als iets interessanter voorbeeld gebruiken wij de Bevolkinsgsgegevens van Nederland 1. Je kunt deze data downloaden door op de link te klikken (als dit niet werkt kan je ook met de rechtermuisknop klikken en voor ‘opslaan als’ kiezen).
Maak in de map waar je je code schrijft een mapje genaamd data aan en sla het gedownloade bestand hier op. Op deze manier weet je zeker waar het bestand opgeslagen is en hoe je deze vanuit Python kunt bereiken.
Wanneer je dit bestand opent in een tekstverwerker (zoals kladblok of notepad onder Windows), dan zie je dat dit bestand bestaat uit getallen en namen, gescheiden door een ; en omsloten door aanhalingstekens ("). Het ziet er misschien wat rommelig uit, maar door deze manier van opschrijven is het heel makkelijk voor een computer om vanuit dit tekstbestand een tabel op te bouwen.
In Python kan je het bestand nu heel makkelijk inladen:
import pandas as pd
data = pd.read_csv('data/Kerncijfers_Wijken_Buurten_211122.csv', delimiter=';', quotechar='"')
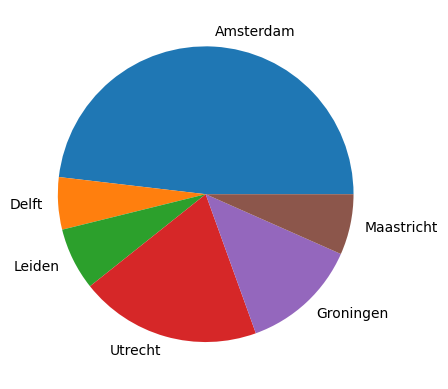
Een voorbeeld van het gebruikvan pandas staat hieronder. Kun je dit voorbeeld aanpassen zodat er meer studentensteden in opgenomen worden?
import pandas as pd
import matplotlib.pyplot as plt
# Let op dat je het bestand op de goede plek hebt opgeslagen!
data = pd.read_csv('data/Kerncijfers_Wijken_Buurten_211122.csv',
delimiter=';',
quotechar='"')
# Lijst met steden
steden = ['Amsterdam', 'Delft', 'Leiden', 'Utrecht', 'Groningen', 'Maastricht']
# Dict waarin we het resultaat gaan opslaan
steden_en_inwoners = {}
# Loop over alle steden in de lijst heen
for stad in steden:
# Filter de data zodat alleen de huidige stad overblijft
stad_data = data[ data['Gemeentenaam_1'].str.contains(stad) ]
# Filter de data zodat we alleen de rij die over de hele
# gemeente gaat overhouden
stad_data_gem = stad_data[ stad_data['WijkenEnBuurten'].str.contains('GM') ]
# Sla het aantal inwoners van de huidige stad op in de
# daarvoor bestemde variabele (een dict)
steden_en_inwoners[stad] = stad_data_gem['AantalInwoners_5'].values[0]
# Print het resultaat
print(steden_en_inwoners)
plt.pie(steden_en_inwoners.values(), labels=steden_en_inwoners.keys())
plt.show()
{'Amsterdam': 873338, 'Delft': 103581, 'Leiden': 124093, 'Utrecht': 359370, 'Groningen': 233273, 'Maastricht': 120227}
Soms is het makkelijker om bij het inlezen van data de eerste X regels van het bestand over te slaan, bijvoorbeeld als het databestand begint met een paar regels ter info in plaats van de data zelf. Dat overslaan kun je eenvoudig doen door skiprows=X toe te voegen aan het inleescommando, bijvoorbeeld:
data = pd.read_csv('<filename>', skiprows=6, delimiter=';')
2.4.3. Excel-bestanden#
Ook Excel-bestanden kunnen heel makkelijk door pandas ingelezen worden. Hier moet je alleen wel een aanvullende module voor installeren: xlrd. Dit kan je, net als hiervoor, doen met pip:
pip install xlrd
Laten we eens proberen een Excel-bestand in te lezen met de verkiezingsdata van de Amerikaanse presidentsverkiezingen uit Chicago 2. Net als hiervoor kan je het bestand opslaan in een map data, als submap van degene waar je jouw python-code schrijft.
Wanneer je het bestand gedownload hebt kan je als volgt het excel bestand inlezen (als de data eenmaal ingelezen is, werkt het DataFrame precies zoals je eerder gewend was):
import pandas as pd
data = pd.read_excel('data/ChicagoElections.xls')
print(data.head(10))
Chicago Board of Election Commissioners Unnamed: 1 \
0 NaN NaN
1 2020 General Election - 11/3/2020 NaN
2 NaN NaN
3 President & Vice President, U.S. NaN
4 NaN NaN
5 Votes Joseph R. Biden & Kamala D. Harris
6 1139222 940319
7 NaN NaN
8 Ward 1 NaN
9 Precinct Votes
Unnamed: 2 Unnamed: 3 \
0 NaN NaN
1 NaN NaN
2 NaN NaN
3 NaN NaN
4 NaN NaN
5 % Donald J. Trump & Michael R. Pence
6 82.54% 180271
7 NaN NaN
8 NaN NaN
9 Joseph R. Biden & Kamala D. Harris %
Unnamed: 4 Unnamed: 5 \
0 NaN NaN
1 NaN NaN
2 NaN NaN
3 NaN NaN
4 NaN NaN
5 % Howie Hawkins & Angela Walker
6 15.82% 6383
7 NaN NaN
8 NaN NaN
9 Donald J. Trump & Michael R. Pence %
Unnamed: 6 Unnamed: 7 \
0 NaN NaN
1 NaN NaN
2 NaN NaN
3 NaN NaN
4 NaN NaN
5 % Gloria La Riva & Leonard Peltier
6 0.56% 2727
7 NaN NaN
8 NaN NaN
9 Howie Hawkins & Angela Walker %
Unnamed: 8 Unnamed: 9 \
0 NaN NaN
1 NaN NaN
2 NaN NaN
3 NaN NaN
4 NaN NaN
5 % Brian Carroll & Amar Patel
6 0.24% 1493
7 NaN NaN
8 NaN NaN
9 Gloria La Riva & Leonard Peltier %
Unnamed: 10 Unnamed: 11 \
0 NaN NaN
1 NaN NaN
2 NaN NaN
3 NaN NaN
4 NaN NaN
5 % Jo Jorgensen & Jeremy ''Spike'' Cohen
6 0.13% 8029
7 NaN NaN
8 NaN NaN
9 Brian Carroll & Amar Patel %
Unnamed: 12 Unnamed: 13
0 NaN NaN
1 NaN NaN
2 NaN NaN
3 NaN NaN
4 NaN NaN
5 % NaN
6 0.70% NaN
7 NaN NaN
8 NaN NaN
9 Jo Jorgensen & Jeremy ''Spike'' Cohen %
(Met data.head(10) laten we alleen de eerste 10 rijen van de data in DataFrame data printen. Merk op dat als je data.head() in de console gebruikt, je direct de output te zien krijgt. Vanuit een script moet je er nog print() omheen zetten.)
- 1
Bron: CBS Opendata.
- 2